Timer Nodes in Message Broker
Scenario 1:- Usage of TimeoutNotification Node in a flow which fires automatically when a flow has been deployed onto the ExecutionGroup.
Step 1 :- Create a message flow as appears below:-
Step 1 :- Create a message flow as appears below:-
Step 2:- Configure the TimeoutNotification Node as follows :-

Step 3:- Copy the following ESQL Code onto Compute Node :-

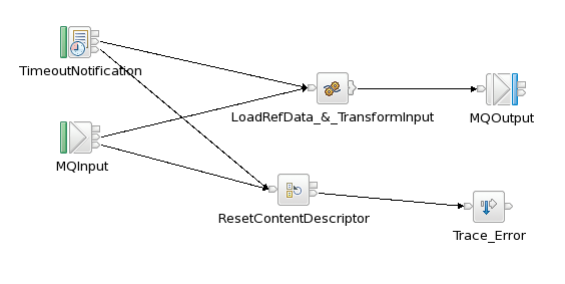
The above flow shows
how to use the first trigger of TimeoutNotification node which happens immediately
after the flow is deployed into the Execution Group or at flow startup. The
compute node ‘LoadRefData_&_TransformInput’ checks whether the reference data
is present/loaded in shared variable. If not, it will retrieve the reference
data using db select query and store it in shared variable.Then this compute
node does the transformation of message payload using the reference data and generates
the output payload. This way we make sure that the reference data is always
loaded on the message flow startup before any input message is processed by
MQInput node.The shared variable makes the reference data available to all the
subsequent messages processed by the message flow.
An Reset Content
Descriptor (RCD) node after the Catch node prevents an exception being thrown
by the Trace node in the case where a message generated by a
TimeoutNotification node or MQInput node cannot be parsed by the Trace node. The
RCD node resets the domain to BLOB.
*********************************************************************************
Step 1:- Create a flow as shown below:-
 Triggering a message flow using configurable trigger parameters (start time, count,
Triggering a message flow using configurable trigger parameters (start time, count,
Interval)

Possible scenarios:-
This scenario would occur if we need the cached data in execution group to be refreshed at certain time interval and this interval is not fixed or predefined. Also the operations/support team wants to drive the event trigger for cache refresh after they update the reference database. This is expected to be handled with minimum process/impact.
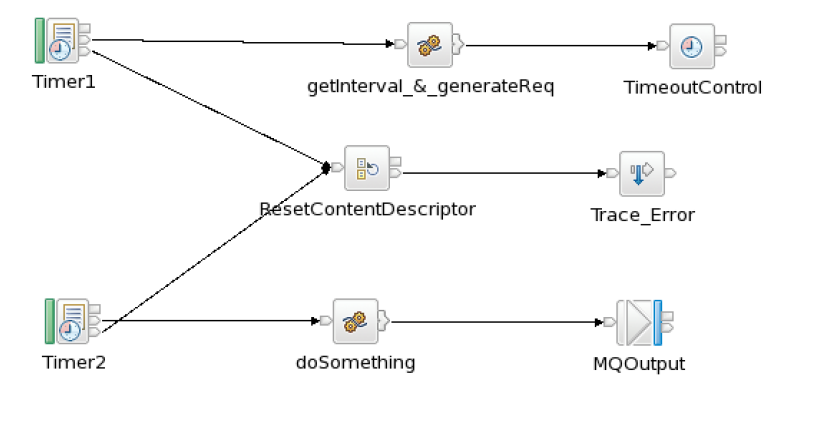
Programming pattern.Given these requirements, the first option would be to provide a separate message flow starting with MQInput node. The operations/support person would put a predefined XML message onto the MQ queue and the message flow would have logic to refresh the cached data in execution group’s JVM.But this approach introduces once more component flow and possibly a java program to put a predefined message onto the input queue. It adds up manual steps and another point of failures for support team.So let’s evaluate this pattern which would automatically handle this scenario without using any additional components. The triggering parameters are set configurable in an existing database table where the operations team has access to change it. Then we use a combination of TimeoutNotification and TimeoutControl nodes as shown in below diagram.
The below sample code shows how to trigger the flow with the ‘Interval’ value configured in database table. For other parameters (start date/time, count), the same logic can be used.
Flow processing.With the TimeoutNotification node (Timer1) in automatic mode, the flow retrieves the interval value from db table at every say 30 minutes (assumed value to optimize db interaction). The ‘getInterval_&_generateReq’ compute node compares this value with previously set value in a shared variable. (A shared variable is set with the interval value retrieved from DB at the first trigger of Timer1).If this newly retrieved interval value is different than the previous value (meaning operations team changed it), the compute node constructs a new TimeoutRequest message containing the new interval and proceeds ahead to trigger the flow with TimeoutNotification node (Timer2). Now on thenew interval comes in effect within maximum 30 min. (Timer1 interval) after the change in DBconfiguration. This gives the operations team the complete flexibility and control to trigger the flowwhenever they want.The database table (APP_PARAM) has below configuration for trigger parameters.


*********************************************************************************
Scenario 2:- Usage of TimeoutNotification Node & TimeoutControl node in a flow
*********************************************************************************
Interval)
Possible scenarios:-
This scenario would occur if we need the cached data in execution group to be refreshed at certain time interval and this interval is not fixed or predefined. Also the operations/support team wants to drive the event trigger for cache refresh after they update the reference database. This is expected to be handled with minimum process/impact.
Programming pattern.Given these requirements, the first option would be to provide a separate message flow starting with MQInput node. The operations/support person would put a predefined XML message onto the MQ queue and the message flow would have logic to refresh the cached data in execution group’s JVM.But this approach introduces once more component flow and possibly a java program to put a predefined message onto the input queue. It adds up manual steps and another point of failures for support team.So let’s evaluate this pattern which would automatically handle this scenario without using any additional components. The triggering parameters are set configurable in an existing database table where the operations team has access to change it. Then we use a combination of TimeoutNotification and TimeoutControl nodes as shown in below diagram.
The below sample code shows how to trigger the flow with the ‘Interval’ value configured in database table. For other parameters (start date/time, count), the same logic can be used.
Flow processing.With the TimeoutNotification node (Timer1) in automatic mode, the flow retrieves the interval value from db table at every say 30 minutes (assumed value to optimize db interaction). The ‘getInterval_&_generateReq’ compute node compares this value with previously set value in a shared variable. (A shared variable is set with the interval value retrieved from DB at the first trigger of Timer1).If this newly retrieved interval value is different than the previous value (meaning operations team changed it), the compute node constructs a new TimeoutRequest message containing the new interval and proceeds ahead to trigger the flow with TimeoutNotification node (Timer2). Now on thenew interval comes in effect within maximum 30 min. (Timer1 interval) after the change in DBconfiguration. This gives the operations team the complete flexibility and control to trigger the flowwhenever they want.The database table (APP_PARAM) has below configuration for trigger parameters.
The following ESQL code is written in the ‘getInterval_&_generateReq’ node above.